Check out the code for this project here
Modeling Consumer Behavior with K-Nearest Neighbors
For this project I built a machine learning model to predict whether an online shopper will actually complete a purchase or leave the website. I made this project was for Harvard's CS50’s Introduction to Artificial Intelligence with Python. This was a good project to learn about the k-Nearest Neighbors (k-NN) classifier.
The Architecture
For this project I had a dataset from roughly 12,000 user sessions that is from the footprints of users browsing the internet. This data contains: how many informational pages the user visited, how long they lingered, their operating system, and whether it was a weekend.
As machine learning models are only able to understand numbers we had to translate and clean the data which I do with the load_data function. Here I wrote functions that map text strings to intergers. For example it converts "Jan" through "Dec" into index values 0 through 11.
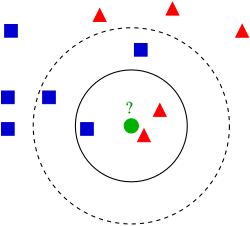
The Geometry of K-Nearest Neighbours
I then predict if a new user will buy something using a train_model function that uses the k-Nearest Neighbours (KNeighborsClassifier) algorithm. The k-NN algorithm treates every single users data as a cooridnate in an n-dimensional space.
Then I split my data into a test a training section where I have 40% for testing. If a new user enters the website puts them in the same space and calculates the distance between the new user and all the historical users using the Euclidean distance formula:
In this project I set n_neighbors=1. What this means is that the AI looks around and finds the closes historical user to the new user and will assume that they behave in the same way. For example if their colsest historical neighbour bought shoes the AI will assume the new user will as well.
Why "Accuracy" is a Trap
Here I an evaluate function that evaluates the model. However, we need to be careful about this.. For example if 15% of users actually complete a purchase and we have an Ai that guesses no everytime it would still be 85% accurate but would be pretty useless to us.
To resolve this problem we use two metrics:
-
Sensitivity (True Positive Rate): Out of all the people who actually made a purchase what percentage did the AI correctly predict?
-
Specificity (True Negative Rate): Out of all the people who didn't buy anything what percentage did the AI correctly ignore?
We want to tray and get the AI to balance these two metrics.